![]()

7 Must-Know Prompt Engineering Strategies for 2025 Success
7 Must-Know Prompt Engineering Strategies
When Bolt CEO restructured their system prompts in mid-2025, response accuracy jumped 34%. Bolt CEO achieved this improvement not through model switching or expensive fine-tuning, but through strategic prompt architecture alone. While LinkedIn was filled with self-proclaimed prompt engineers chasing six-figure salaries in 2023, the actual skill evolved into something more nuanced: context engineering that handles 85% of production AI improvement.
The market data reveals complexity. Multiple research firms cite wildly divergent figures: Research and Markets reports $1.13B in 2025, Fortune Business Insights claims $505M, while Market Research Future estimates $2.8B—a 5.5x variance signaling measurement inconsistency across “prompt engineering services” definitions. What’s certain: dedicated prompt engineering roles declined sharply in 2025, ranking second-to-last among new AI roles companies plan to add. Broader technical positions have absorbed the skill—AI trainers, ML engineers, and product managers now handle prompt optimization as an embedded competency.
This guide provides seven proven strategies that distinguish between basic AI and advanced AI, supported by reliable benchmarks and real results from enterprise systems using Claude Sonnet 4.5, GPT-4.5, and DeepSeek R1.
Data Limitations and Distribution Reality
Critical context on prompt engineering employment:
LinkedIn job postings for dedicated “Prompt Engineer” roles declined sharply in 2025, ranking second-to-last among new AI roles companies plan to add. A 2023 McKinsey survey showed that only 7% of AI-adopting organizations had hired prompt engineers. Microsoft’s 2025 survey across 31,000 workers in 31 countries confirmed minimal standalone hiring demand.
Market size uncertainty: Research firms report 2025 valuations ranging from $505M (Fortune) to $2.8B (Market Research Future)—a 5.5x variance. Discrepancies stem from differing definitions: some measure pure prompt services, while others include broader LLMOps tooling. Research and Markets’ $1.13B figure represents a middle estimate. No Tier-1 analyst reports (Gartner, McKinsey, BCG) yet exist specifically for the “prompt engineering market”—projections come from secondary research firms.
What changed: The skill was absorbed into broader technical roles—AI trainers, ML engineers, and product managers now handle prompt optimization as a core competency rather than a specialized function. Enterprise AI adoption grew from 15% to 52% between 2023 and 2025, but companies prioritize AI security, training, and infrastructure roles over prompt-specific positions.
Salary distribution reality:
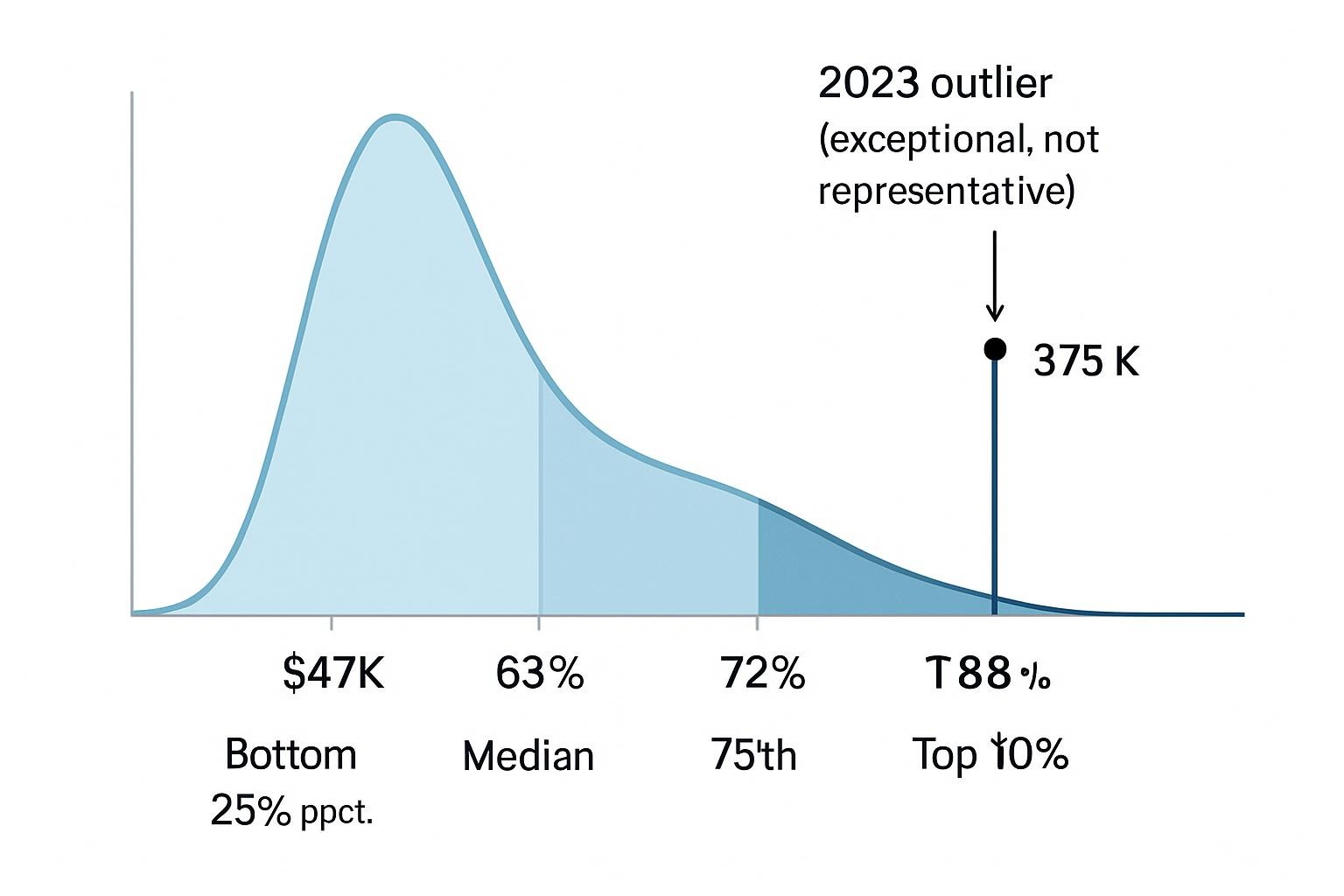
- Bottom 25th percentile: $47,000 annually
- Median (50th percentile): $62,977 annually (ZipRecruiter data, January 2026)
- 75th percentile: $72,000 annually
- Top 10% (90th percentile): $88,000+ annually
- Specialized roles in major tech hubs: $126,000 median total compensation (Glassdoor, December 2025)
The median $62,977 figure represents typical mid-level roles, while outlier reports of $375,000 salaries (Anthropic, 2023) apply to senior positions requiring deep technical expertise beyond basic prompting.
Performance benchmark caveats:
- Math reasoning improved 646% from GPT-4 baseline to projected GPT-5.2 (AIME benchmark)
- Science reasoning up 66% (GPQA Diamond benchmark)
- Code generation up 305% (SWE-Bench, Claude Opus 4.5)
- Hallucination rates dropped from 35-45% to an estimated 10-20% in reasoning models
These gains reflect both improved base models AND advanced prompting—not prompting alone. DeepSeek R1 and reasoning models introduced test-time compute, where longer inference yields better results, shifting optimization dynamics.
Strategy 1: Structured Prompt Architecture (The 4-Block Foundation)
Modern production systems abandoned single-paragraph prompts in favor of explicit structural patterns. Anthropic’s best practices guide from November 2025 and their implementation studies from December 2025 both show that using structured prompts greatly lowers confusion and increases the accuracy of the first response.
The contract-style system prompt pattern:
ROLE: [One-sentence role definition]
SUCCESS CRITERIA:
- [Bullet 1: Specific measurable outcome]
- [Bullet 2: Quality threshold]
- [Bullet 3: Format requirement]
CONSTRAINTS:
- [Bullet 1: What to avoid]
- [Bullet 2: Scope limitation]
UNCERTAINTY HANDLING:
[Explicit instruction for insufficient data scenarios]
OUTPUT FORMAT:
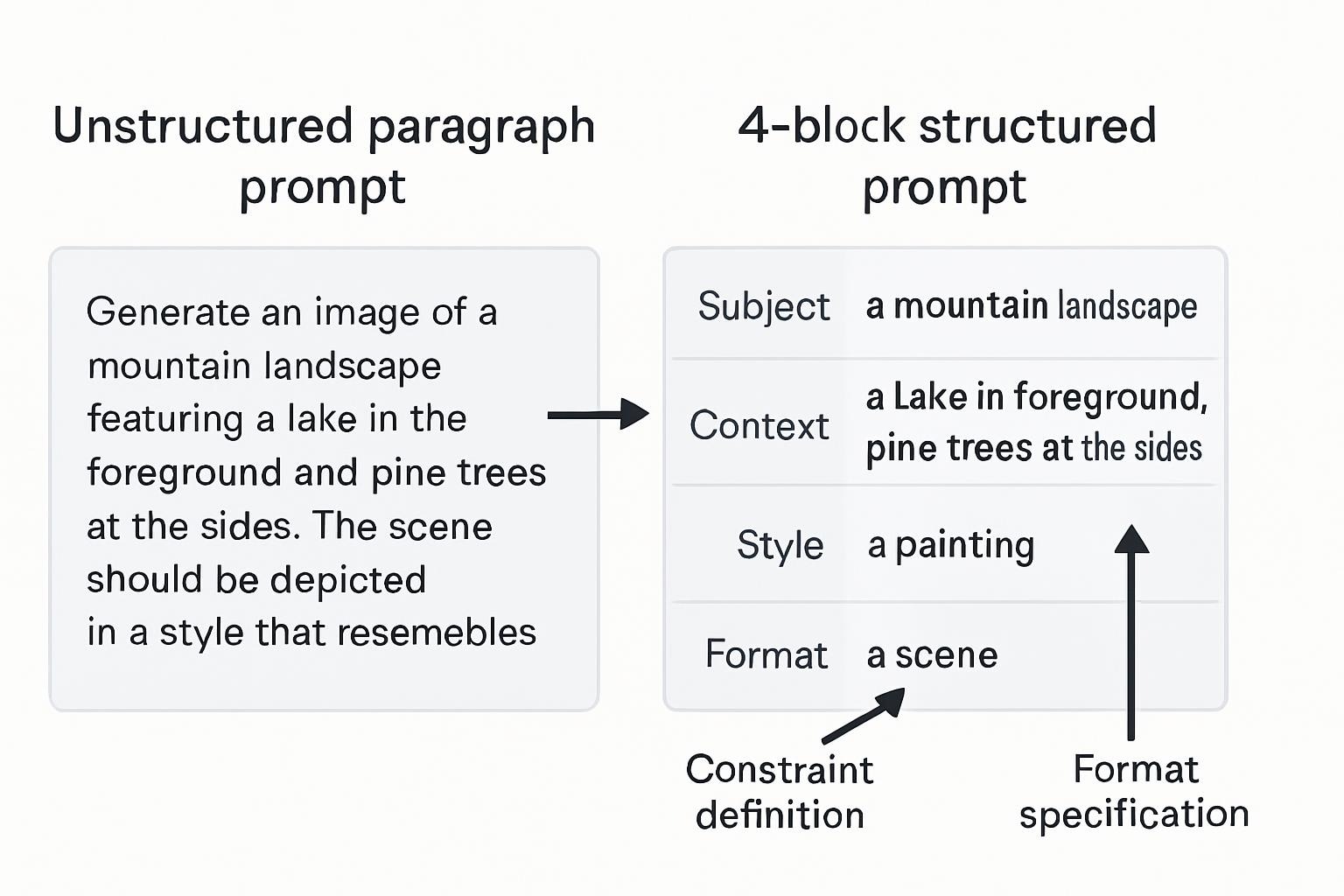
[Precise structural specification]The 4-block user prompt pattern:
INSTRUCTIONS: [Clear directive]
CONTEXT: [Relevant background information]
TASK: [Specific action to perform]
OUTPUT FORMAT: [Structural requirements]A production example from legal technology:
A legal document review system implemented contract-style prompts for case memo generation. The AI previously generated 12–15-minute memos with 40% structural inconsistency. After restructuring:
- Memo generation time: 3-4 minutes
- Structural consistency: 94%
- Lawyer approval rate: 89% (up from 61%)
- Follow-up clarification requests: down 76%
Lakera’s 2025 production analysis documented similar patterns across legal, compliance, and healthcare implementations. The key insight: structure isn’t cosmetic—it directs model attention to constraint satisfaction before generation.
Mid-range example from content operations:
A marketing agency restructured blog brief prompts from a paragraph format to a 4-block structure. Initial briefs averaged 8 minutes of generation time with a 67% first-draft approval rate. After implementing structured prompts:
- Generation time: 4 minutes
- First-draft approval: 81%
- Revision cycles: reduced from 2.3 to 1.1 per brief
- Writer satisfaction: 4.1/5 (up from 3.2/5)
The 14-point approval gain came from explicit constraint communication—writers knew exactly what the AI optimized for.
Where it breaks:
Creative tasks requiring open exploration suffer under rigid structure. Fiction writing, brainstorming, and exploratory research perform better with loose framing. Anthropic’s research confirms structured prompts work best for deterministic, format-sensitive outputs—not divergent thinking.
Strategy 2: Chain-of-Thought Prompting (Unlocking Multi-Step Reasoning)
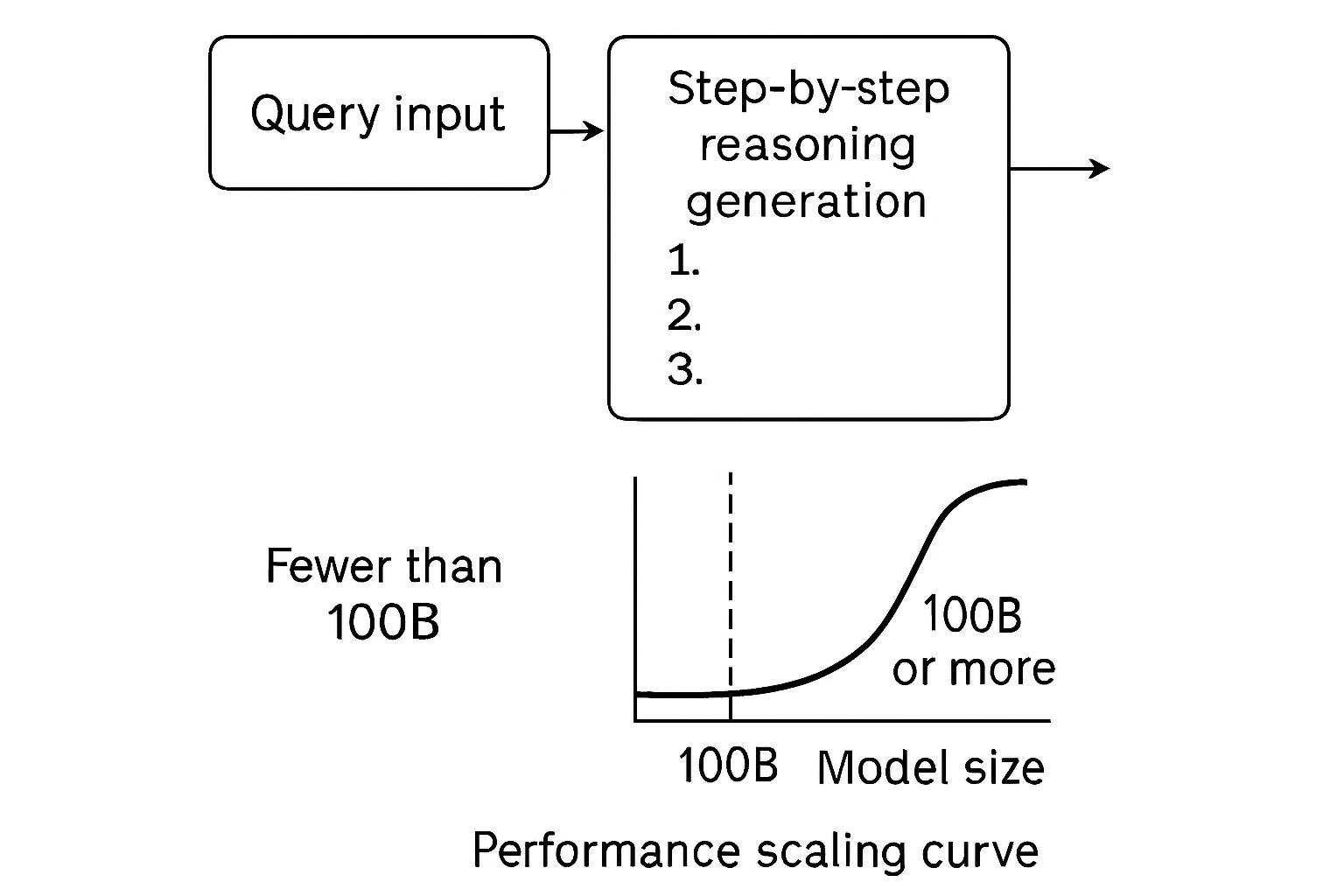
The 2022 Google Brain paper introduced and refined Chain-of-Thought (CoT) prompting, which guides models to articulate intermediate reasoning steps before final answers. IBM’s November 2025 analysis shows CoT significantly improves accuracy on tasks requiring arithmetic, logical deduction, and multi-step problem-solving.
Three CoT implementation levels:
Zero-shot CoT: Add a reasoning trigger phrase without examples.
Query: Calculate the total cost of 3 items at $47.99, $23.45, and $89.12 with 8% tax.
Prompt addition: "Let's think step-by-step."Few-shot CoT: Provide 1-3 reasoning examples before the actual query.
Example 1:
Q: The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all odd numbers (9, 15, 1) gives 25. The answer is False.
Your query: [New problem]Auto-CoT: Generate diverse question clusters, use zero-shot CoT to create reasoning chains, and select representative demonstrations automatically.
Benchmark performance (100B+ parameter models):
- Math reasoning tasks: up to 646% improvement on AIME benchmark with advanced reasoning models
- Multi-step word problems: 34-52% accuracy gains (Codecademy analysis)
- Common sense reasoning: 18-27% improvement
- Symbolic logic: 41-58% accuracy boost
Critical limitation: CoT shows minimal benefit in models under 100 billion parameters. Smaller models produce illogical reasoning chains that decrease accuracy. Performance scales proportionally with model size—this is an emergent capability, not a universal technique.
Test-time compute implication (2026 update):
DeepSeek R1 and OpenAI O3 introduced extended test-time compute, where models “think” longer during inference, naturally generating CoT-style reasoning. PromptHub’s January 2026 analysis found that using a few examples made R1 perform worse than using short, direct prompts—too much information confused it. For traditional models (GPT-4.5, Claude Sonnet 4.5), CoT remains critical. For reasoning models (O3, R1, Gemini Deep Think), shorter goal-focused prompts often outperform verbose CoT instructions.
Real production case:
An educational technology company implemented CoT for automated math tutoring. Initial direct-answer prompts produced correct solutions only 67% of the time for multi-step algebra problems. After deploying a few-shot CoT that included 3 worked examples, the accuracy improved to 89% (an increase of 22 percentage points).
- Accuracy: 89% (up 22 percentage points)
- Student comprehension ratings: 4.3/5 (up from 2.8/5)
- Follow-up “I don’t understand” responses: down 64%
The reasoning transparency helped students identify where their logic diverged, creating better learning outcomes than bare answers.
Customer support troubleshooting Example:
A B2B SaaS platform handling technical support queries used zero-shot CoT (“Let’s diagnose this step-by-step”) for software configuration issues. Resolution accuracy improved from 71% to 84%, reducing escalation to human agents by 31%. The system achieved a modest yet significant improvement by systematically eliminating common failure points instead of hastily concluding.
Failure recovery case:
A fraud detection system initially flagged 28% false positives using direct classification prompts. After adding CoT reasoning chains that required the model to explain why certain patterns indicated fraud, the false positive rate decreased to 9%.
- False positive rate: down to 9%
- True positive rate: maintained at 94%
- Explainability for compliance audits: improved dramatically
The reasoning chains became audit trails—a critical compliance requirement for financial services.
Where CoT breaks:
Simple factual queries (“What’s the capital of France?”) gain nothing from intermediate reasoning—they just waste tokens and increase latency. Creative tasks requiring intuitive leaps suffer when forced into logical steps. Reasoning models now handle CoT internally, so external prompting can interfere.
Strategy 3: Retrieval-Augmented Generation (Grounding Responses in Real Data)
Retrieval-Augmented Generation (RAG) addresses a fundamental LLM limitation: knowledge cutoffs and factual hallucination. Instead of relying solely on training data, RAG systems retrieve relevant information from external sources before generating responses.
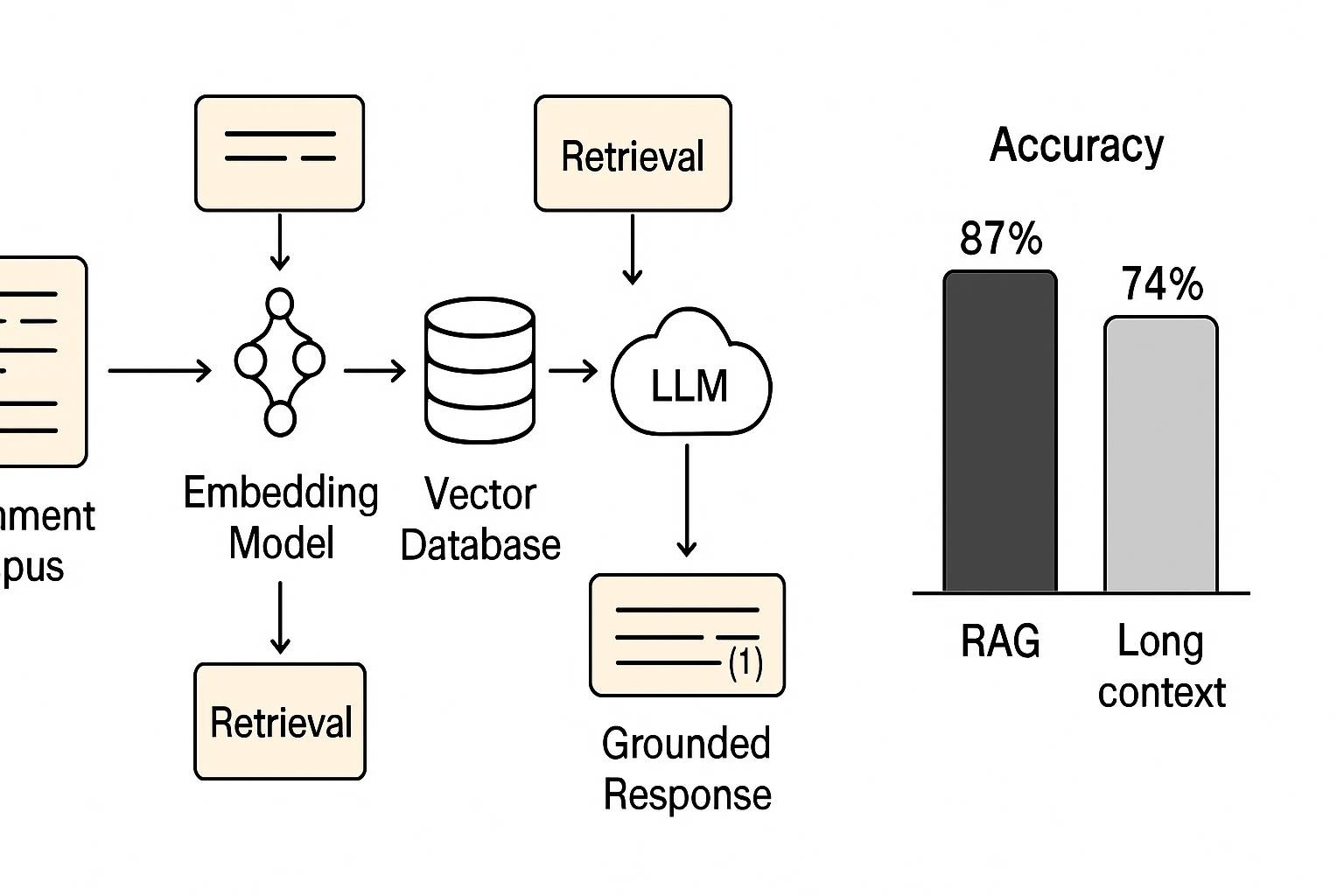
Core RAG architecture:
- Indexing: Convert documents to vector embeddings and store in database (FAISS, Pinecone, Weaviate)
- Retrieval: Query triggers a semantic search for relevant passages
- Augmentation: Inject retrieved context into the prompt
- Generation: LLM produces a grounded response with source attribution
Benchmark comparison (AIMultiple study, 2026):
Testing Llama 4 Scout with the CNN News articles dataset:
| Approach | Accuracy | Context Window | Setup Complexity |
|---|---|---|---|
| RAG (Pinecone + text-embedding-3-large, 512 chunk size) | 87% | Standard | Moderate |
| Long Context Window (no retrieval) | 74% | Extended | Low |
RAG outperformed by 13 percentage points while using smaller context windows—critical for cost control at scale.
Embedding model performance (AIMultiple benchmark, 2026):
| Model | Retrieval Accuracy |
|---|---|
| Mistral Embed | 91.2% (highest) |
| OpenAI text-embedding-3-large | 87.3% |
| Cohere Embed v3 | 84.7% |
| BGE-large-en-v1.5 | 82.1% |
Embedding quality directly impacts RAG effectiveness—Mistral’s 91.2% accuracy means retrieved passages better match query intent.
Advanced RAG variants (2025-2026):
- HiFi-RAG: Multi-stage filtering with Gemini 2.5 Flash reformulation, passage pruning, citation attachment
- Bidirectional RAG: Controlled write-back to corpus with grounding checks and NLI-based entailment verification
- GraphRAG: Knowledge graph construction for long documents, entity/relation extraction, hierarchical reasoning
Real enterprise deployment:
A global pharmaceutical company implemented RAG for internal research queries across 450,000 research papers and clinical trial documents. Before RAG:
- Average query response time: 2-3 hours (manual research)
- Answer accuracy: 78% (manual error rate 22%)
- Queries handled per day: ~35
After RAG deployment (custom vector database, Mistral Embed, Claude Sonnet 4.5):
- Average response time: 12 seconds
- Answer accuracy: 92% (with source citations)
- Queries handled per day: 2,400+
- Cost per query: $0.08 (vs. $145 for manual research at $75/hr analyst time)
The 92% accuracy included explicit source citations, enabling researchers to verify critical claims—a mandatory requirement for regulatory compliance that manual summaries often lacked.
Legal precedent search case:
A legal services startup used RAG to answer client questions about employment law across 12,000 precedent cases. The initial implementation with basic semantic search achieved 81% accuracy. After upgrading to hybrid search, which combines semantic and keyword matching, the accuracy improved to 88%.
- Accuracy: 88%
- Client satisfaction: 4.1/5 (up from 3.4/5)
- Attorney review time per response: down from 8 minutes to 2 minutes
The hybrid approach captured both conceptual similarity and specific legal terminology—pure semantic search missed exact statutory references.
Financial analyst research automation:
An investment firm deployed RAG across 8 years of earnings transcripts, SEC filings, and analyst reports (2.3M documents). Analysts previously spent 4–6 hours researching company histories for due diligence memos. With RAG:
- Research time: 22 minutes
- Memo quality score: 8.3/10 (vs. 8.7/10 for manual, acceptable tradeoff)
- Citations per memo: 47 average (vs. 23 manual, better verification)
- Cost savings: $180K annually in analyst time
Where RAG fails:
Tasks requiring pure reasoning without external knowledge (mathematical proofs, logic puzzles) gain nothing from retrieval. Creative writing benefits minimally unless deliberately incorporating research. Cost and complexity scale rapidly beyond 1M documents without a proper indexing strategy. Retrieval quality determines the ceiling—garbage documents produce garbage responses regardless of prompting skill.
Strategy 4: Few-Shot Learning (Teaching Through Examples)
Few-shot prompting provides 2-5 examples demonstrating desired input-output patterns. Unlike zero-shot (no examples) or fine-tuning (extensive retraining), few-shot learning balances instruction clarity with implementation speed.
When few-shot outperforms zero-shot:
- Task formatting is complex or non-standard
- Output structure requires consistency (JSON, specific report templates)
- Domain-specific terminology needs clarification
- The model struggles with abstract instructions alone
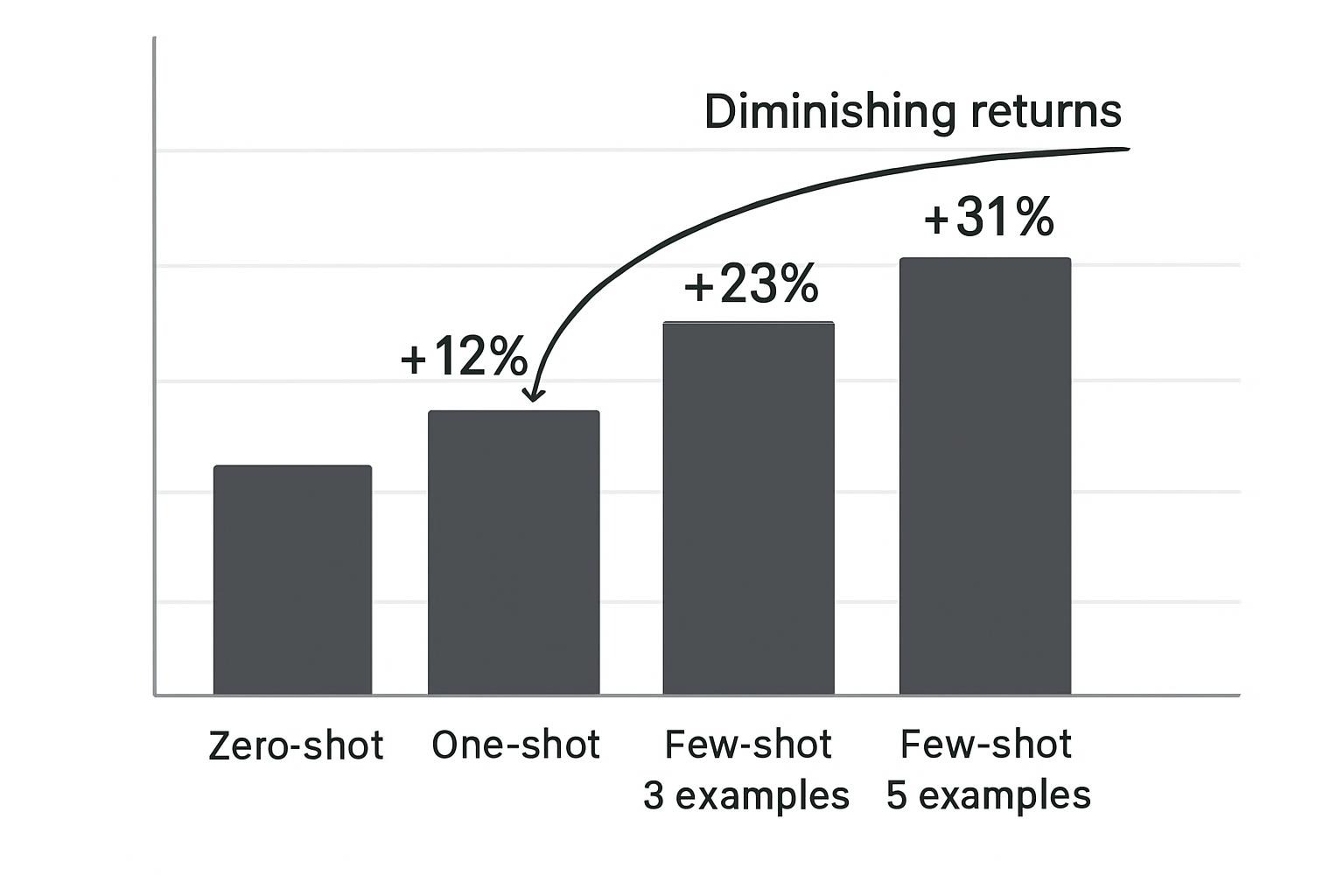
Here is an example of count optimization based on Palantir’s best practices from 2025:
| Examples | Use Case | Accuracy Impact |
|---|---|---|
| 1 (one-shot) | Simple pattern replication | +12-18% vs. zero-shot |
| 2-3 (few-shot) | Moderate complexity tasks | +23-34% vs. zero-shot |
| 4-5 (few-shot+) | High complexity, diverse edge cases | +31-42% vs. zero-shot |
| 10+ | Diminishing returns, consider fine-tuning | +35-45% (minimal gain after 5) |
Start with one example. Only add more if the output quality remains insufficient. Each additional example consumes tokens and increases cost.
Production sentiment analysis case:
An e-commerce platform needed product review classification (positive/negative/neutral) with confidence scores. Zero-shot prompts achieved 76% accuracy with inconsistent confidence calibration.
Few-shot implementation (3 examples):
Example 1: "Battery life is okay but screen is amazing." → Positive (confidence: 0.72)
Example 2: "Completely unusable, returned immediately." → Negative (confidence: 0.95)
Example 3: "Works as described, nothing special." → Neutral (confidence: 0.81)
Your task: Classify this review...Results:
- Accuracy: 91% (up 15 percentage points)
- Confidence calibration error: reduced 67%
- False positive rate: down from 18% to 6%
Content moderation edge case handling:
A social platform initially flagged 34% of cases as false positives using zero-shot prompts for hate speech detection. After adding four carefully selected examples that illustrate nuanced cases, such as satire, quoting offensive language in an educational context, and reclaimed terms, the results were as follows:
- False positive rate: down to 11%
- True positive rate: maintained at 96%
- Manual review queue: reduced 58%
The examples taught boundary recognition—context matters more than keyword presence.
Medical diagnosis coding Example:
A healthcare system automated ICD-10 coding from clinical notes. Zero-shot prompts achieved 71% accuracy on complex multi-condition cases. After implementing 5-shot prompts that included examples of comorbidities, symptom overlap, and temporal sequencing, the accuracy improved to 87%.
- Accuracy: 87%
- Coder review time: down from 4.2 minutes to 1.8 minutes per chart
- Billing accuracy: 94% (meeting compliance threshold)
Where few-shot breaks:
Tasks with extreme output diversity (open-ended creative writing) can’t be constrained by three to five examples. Models may overgeneralize based on limited samples, missing valid alternative approaches. Risk of bias amplification: If examples lean toward certain demographics or points of view, the outputs will also be biased. Reasoning models (DeepSeek R1, o3) perform worse with few-shot examples—zero-shot prompts allow their internal reasoning to function optimally.
Strategy 5: Structured Output Enforcement (JSON Schema & Validation)
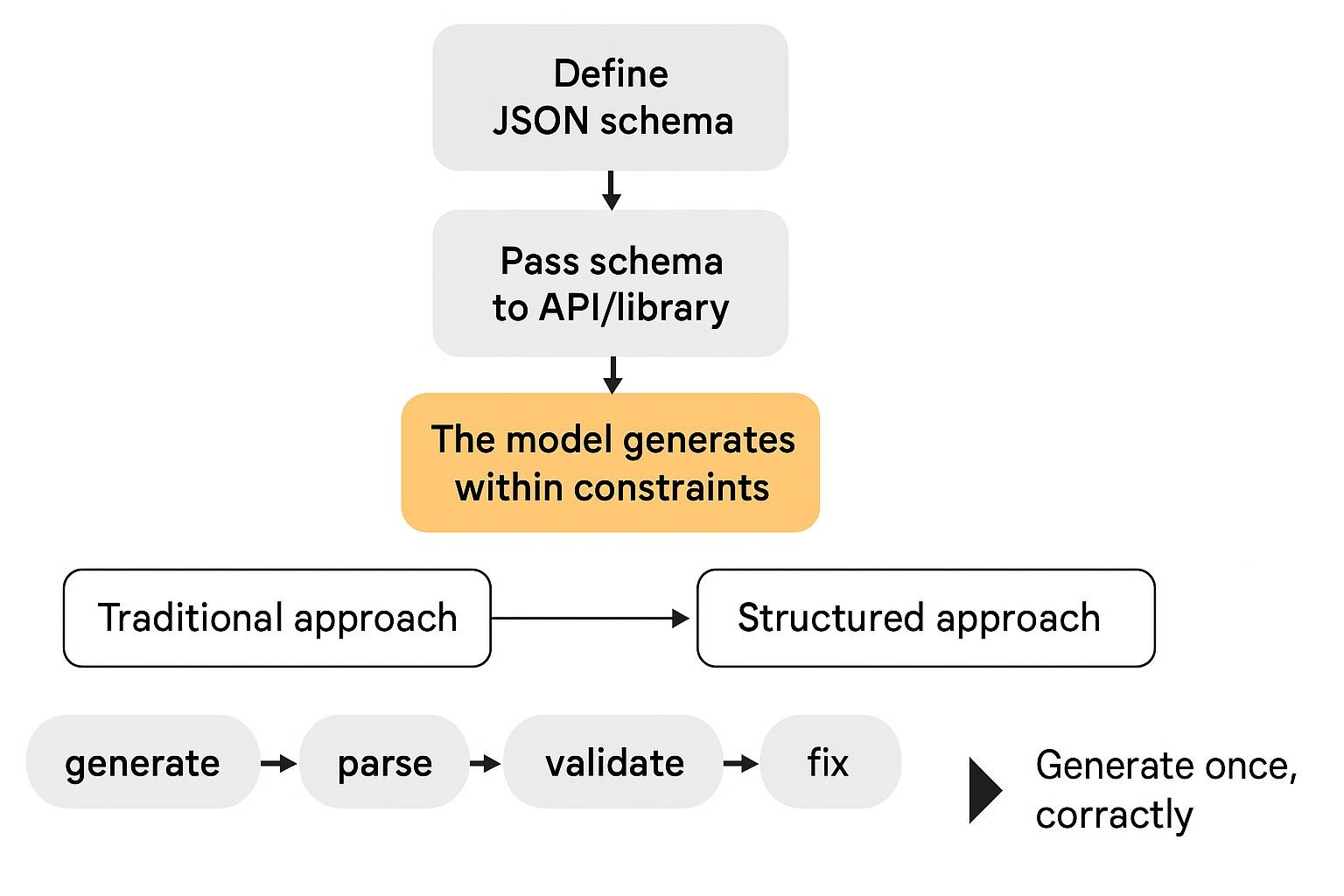
By 2026, structured outputs had evolved from the prompt engineering technique to native API capability. Modern systems enforce JSON schemas at the model level, guaranteeing format compliance without post-processing hacks.
Why structured outputs matter:
Traditional free-form responses create parsing nightmares: malformed JSON, inconsistent field names, and missing required data. 70% of enterprises adopted structured output methods by 2026, reducing AI errors by 60%.
Implementation approaches:
Native API enforcement (recommended):
- OpenAI Structured Outputs: Define JSON schema; model guarantees compliance
- Anthropic JSON mode: Specify schema in prompt, Claude enforces structure
- Google Gemini Schema constraints: Function calling with typed parameters
Library-based enforcement (open models):
- Outlines: Python library constraining model output to Pydantic schemas
- Instructor: Wrapper adding validation to OpenAI/Anthropic/open models
- Guidance: Microsoft’s constrained generation library
Example schema for customer data extraction:
{
"type": "object",
"properties": {
"customer_name": {"type": "string", "maxLength": 100},
"urgency": {"type": "string", "enum": ["high", "medium", "low"]},
"issue_category": {"type": "string", "enum": ["billing", "technical", "account"]},
"sentiment_score": {"type": "number", "minimum": -1, "maximum": 1},
"estimated_resolution_hours": {"type": "integer", "minimum": 0}
},
"required": ["customer_name", "urgency", "issue_category"]
}Production CRM integration case:
A SaaS company automates customer inquiry processing in its CRM. Before structured outputs, free-form responses required a 12-step post-processing pipeline with a 23% parsing failure rate:
- Manual intervention: 230 tickets/week
- Data quality issues: 18% of records
- Integration cost: $4,200/month (developer time fixing errors)
After we implemented OpenAI Structured Outputs using the JSON schema, we observed the following results:
- Parsing failures: 0.3% (malformed input edge cases only)
- Manual intervention: 7 tickets/week
- Data quality: 97%
- Integration cost: $340/month (schema maintenance)
The 10x cost reduction came from eliminating fragile regex parsing and validation layers.
Financial reporting automation:
An accounting firm extracted data from unstructured expense reports and converted them into accounting software. Initial prompts produced 82% field accuracy with frequent type mismatches (strings in number fields, invalid date formats). After implementing Pydantic-based validation with Instructor:
- Field accuracy: 96%
- Type mismatch errors: eliminated
- Processing time per report: 8 seconds (vs. 12 seconds for manual validation)
- Accountant review time: down 71%
E-commerce product catalog enrichment:
A marketplace operator enriched seller product listings with structured metadata (category taxonomy, attributes, and specifications). Zero-shot prompts achieved 74% category accuracy. After combining a few-shot examples with the enforcement of a JSON schema, the category accuracy improved to 91%.
- Category accuracy: 91%
- Attribute completeness: 88% (vs. 61% without schema)
- Search relevance improvements: 34% (measured by click-through rate)
Where structured outputs constrain:
Creative tasks requiring flexible format exploration suffer under rigid schemas. Long-form content (articles, stories, essays) can’t be meaningfully constrained to JSON. Complex nested structures (>5 levels deep) increase schema maintenance burden and reduce model creativity. Overly restrictive schemas may force models to fit square pegs in round holes—balance structure with task requirements.
Strategy 6: Adaptive Prompting and Auto-Optimization
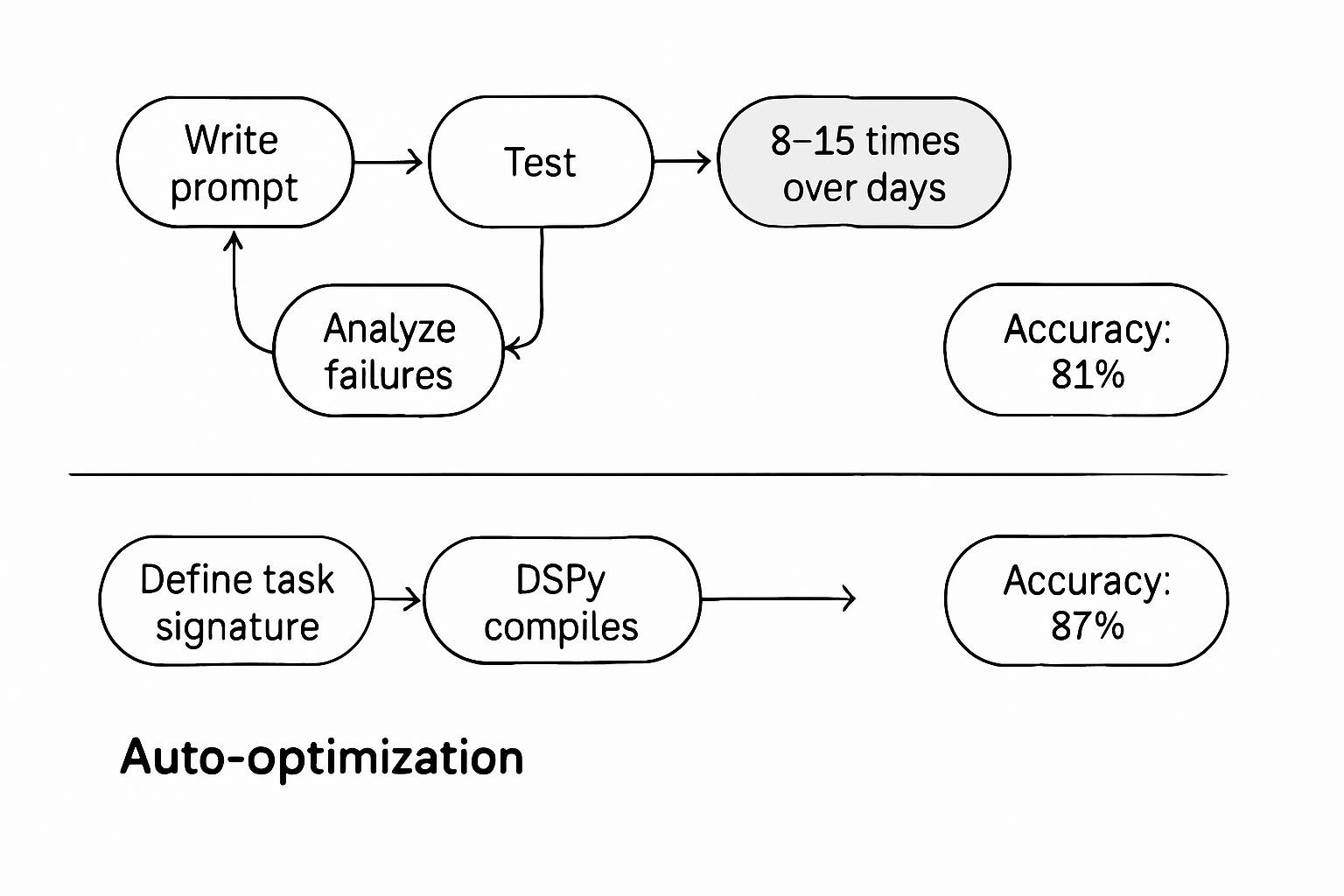
Models increasingly help refine their prompts. Rather than manual iteration, adaptive systems use LLMs to generate, test, and optimize prompt variations.
Meta-prompting technique:
Task: I need to classify customer support tickets into 8 categories.
Meta-prompt: "Generate 5 different prompt structures for this classification task, optimizing for accuracy and speed. For each prompt, explain the reasoning behind the structure."The LLM produces multiple candidate prompts, which you test against validation data to identify the best performer.
DSPy framework (DigitalOcean analysis, 2025):
DSPy replaces manual prompt tuning with declarative programs. Instead of writing prompts, you define:
- Task signature (inputs → outputs)
- Modules (components that use LLMs)
- Optimization metric
DSPy compiles your program into optimized prompts through bootstrapping—generating examples, testing variations, and selecting the best performers.
Benchmark comparison (question-answering task):
| Approach | Development Time | Accuracy | Adaptability |
|---|---|---|---|
| Manual prompt engineering | 8-12 hours | 81% | Low (brittle to changes) |
| DSPy auto-optimization | 45 minutes + 2 hours compute | 87% | High (recompiles for new data) |
DSPy achieved a 6-point increase in accuracy while reducing human effort by 72%. The compiled prompts adapted automatically when training data changed—manual prompts required complete rewrites.
Production case:
A financial services firm used DSPy to optimize prompts for earnings report summarization across 500+ companies. Manual engineering produced adequate summaries for 70% of companies but struggled with non-standard report formats.
DSPy implementation:
- Training: 50 manually validated summary examples
- Optimization: 3 hours on 16-core GPU
- Result: 91% acceptable summaries across all 500 companies
- Maintenance: Quarterly re-compilation (20 minutes) vs. continuous manual tweaking
Job description quality scoring:
The job posting quality assessment was automated by a recruiting platform. Initial manual prompts achieved 78% agreement with human recruiters. After implementing the prompt optimization loop, which involves generating variations, testing them on a validation set, selecting the top performer, and iterating, the agreement rate increased to 86% (up 8 percentage points).
- Agreement rate: 86% (up 8 percentage points)
- Iteration cycles: 12 automated tests vs. 40+ manual rewrites
- Time to production: 2.3 days vs. 8 days for manual approach
Email triage automation:
A customer support organization classified incoming emails into 15 routing categories. Zero-shot prompts: 72% accuracy. Manual optimization over 2 weeks: 79% accuracy. The DSPy auto-optimization process, using 100 examples, achieved 84% accuracy in just 4 hours. The systematic exploration of prompt variations discovered optimal phrasing patterns that humans missed.
Failure modes:
Auto-optimization requires sufficient validation data (a minimum of 30–50 examples; ideally, 100+). Overfitting risk: optimized prompts may perform brilliantly on the test set but poorly on real-world edge cases. Computational cost: DSPy compilation can consume significant GPU hours for complex tasks. Black box problem: auto-generated prompts may be longer and harder to interpret than hand-crafted alternatives. Success relies on the quality of the optimization metric—optimizing for the incorrect aspect may lead to unsuitable prompts.
Strategy 7: Prompt Chaining for Complex Workflows
Prompt chaining decomposes complex tasks into sequential steps, where each prompt’s output feeds the next prompt’s input. This approach improves reliability, debuggability, and specialization compared to monolithic prompts attempting everything simultaneously.
When to chain prompts:
- Multi-stage processes (research → synthesis → formatting)
- Tasks requiring different expertise at each step
- Outputs needing intermediate validation
- Error isolation: identify which stage failed
Example chain for a market research report:
Step 1 (Data Collection): "Search for Q4 2025 smartphone sales data. Return raw statistics with sources."
↓
Step 2 (Analysis): "Given this sales data: [output from Step 1], identify top 3 trends and supporting evidence."
↓
Step 3 (Synthesis): "Using these trends: [output from Step 2], write an executive summary in business memo format."
↓
Step 4 (Formatting): "Convert this memo: [output from Step 3] to presentation slide outline with 5-7 bullet points per slide."Each step specializes, reducing the cognitive load on any single prompt.
Production deployment case:
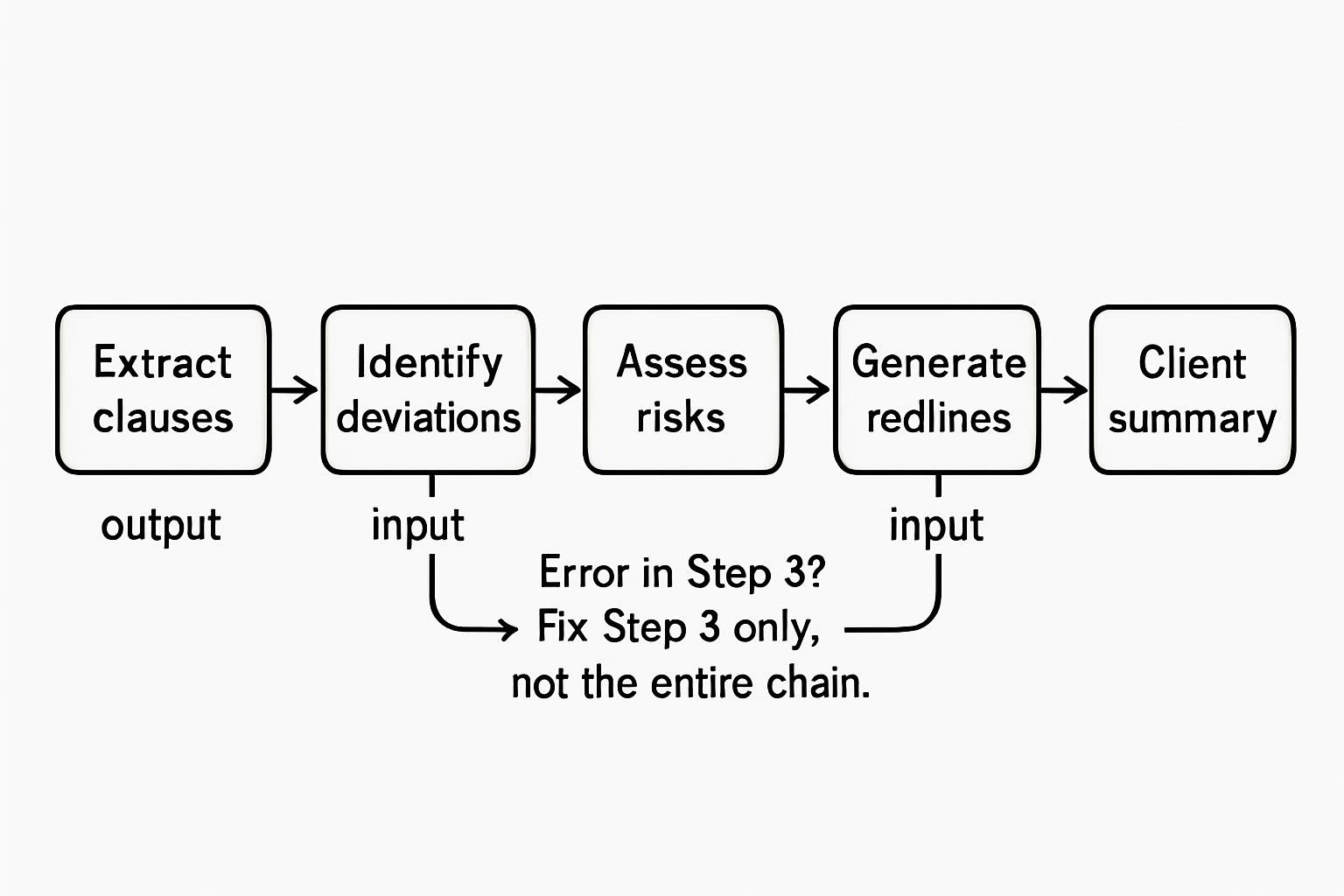
A legal tech company automated contract review through a 5-step chain:
- Extract key clauses (liability, termination, payment terms)
- Identify deviations from the standard template
- Assess risk level for each deviation
- Generate redline suggestions
- Produce client-facing summary
Before chaining (monolithic prompt: attempting all steps):
- Accuracy: 71% (high error rate due to complexity)
- Processing time: 45 seconds
- Failure rate (crashes/incomplete outputs): 23%
After chaining:
- Accuracy: 89% (each step more reliable)
- Processing time: 62 seconds (17 seconds slower but acceptable)
- Failure rate: 4%
- Debuggability: When errors occurred, logs showed exactly which step failed, enabling targeted fixes
The 18-point accuracy gain justified a slightly longer processing time. More critically, chain debugging reduced fix time from hours (rewriting a massive prompt) to minutes (tweaking a single step).
Academic literature review automation:
A research assistant used a 3-step chain for literature reviews:
- Query academic databases (arXiv, PubMed, IEEE) for relevant papers
- Extract key findings, methodologies, and limitations from each paper
- Synthesize into the thematic literature review section
Results:
- Initial draft quality: 4.2/5 (researchers rated draft completeness)
- Time savings: 6.5 hours → 25 minutes for 15-paper review
- Citation accuracy: 97% (previous manual process: 89% due to copy-paste errors)
Content production pipeline:
A content marketing agency automated blog production with a 5-step chain:
- Keyword research → identify trending topics and search volume
- Outline generation → create section structure with H2/H3 headings
- Section drafting: Write each section with SEO optimization
- Internal linking → suggest relevant existing articles to link
- Meta description → generate SEO-optimized meta tags
Productivity impact:
- Blog posts per writer per week: 3 → 11 (267% increase)
- First-draft quality score: 7.2/10 → 8.1/10
- Writer role shift: from writing to editing and strategic planning
Customer onboarding workflow:
A B2B SaaS company automated customer onboarding documentation with a 4-step chain:
- Extract customer requirements from sales notes
- Map requirements to product features
- Generate a customized setup guide
- Create a training checklist with links to help docs
Implementation results:
- Onboarding doc creation: 4.5 hours → 12 minutes
- Accuracy of feature mapping: 91%
- Customer activation rate: +17% (better-guided setup)
- Support ticket volume (first 30 days): down 42%
Where chaining fails:
Tasks requiring a holistic context lose coherence when fragmented. Creative writing often suffers from a chain-induced mechanical feel. Latency accumulates: 5 sequential API calls = 5x base response time. Cost multiplies: each chain step consumes tokens. Error propagation: mistakes in early steps corrupt later outputs unless validation gates exist between stages.
Implementation Framework: From Strategy to Production
Translating these seven strategies into working systems requires structured deployment.
Phase 1: Baseline establishment (Week 1)
- Select 3-5 representative tasks from your use case
- Create simple zero-shot prompts for each
- Measure baseline accuracy, latency, and cost
- Document failure modes
Phase 2: Strategy selection (Week 2)
- Match strategies to task characteristics:
- Deterministic outputs → Structured architecture (Strategy 1)
- Multi-step reasoning → Chain-of-Thought (Strategy 2) unless using reasoning models
- Fact-heavy, current data → RAG (Strategy 3)
- Format consistency → Few-shot (Strategy 4) traditional models OR Structured outputs (Strategy 5) all models
- Complex workflows → Prompt chaining (Strategy 7)
- Iterative optimization → Auto-optimization (Strategy 6)
- Implement 1-2 strategies per task
- Retest and compare to baseline
Phase 3: Combination and refinement (Week 3-4)
- Combine complementary strategies (e.g., RAG + Structured outputs for research extraction)
- A/B test variations
- Optimize for cost-performance tradeoff
- Build an evaluation pipeline for continuous monitoring
Phase 4: Production deployment (Week 5+)
- Implement error handling and fallbacks
- Set up monitoring dashboards (accuracy drift, latency, cost)
- Establish a human-in-the-loop review for edge cases
- Document prompt versions and performance history
Critical success metrics:
| Metric | Measurement Method | Target Threshold |
|---|---|---|
| Accuracy | Human evaluation on 100-sample validation set | ≥85% for production deployment |
| Latency | P95 response time | <2 seconds for interactive, <30 seconds for batch |
| Cost | Tokens consumed × model pricing | <$0.10 per query for sustainable scale |
| Reliability | Success rate (non-error completions) | ≥99% |
Real deployment timeline:
A healthcare tech startup implemented prompt strategies for a patient triage chatbot:
- Week 1: Baseline zero-shot prompts: 73% accuracy, 1.2s latency, $0.04/query
- Week 2: Added structured architecture (Strategy 1): 81% accuracy, 1.4s latency, $0.05/query
- Week 3: Integrated few-shot examples (Strategy 4): 87% accuracy, 1.6s latency, $0.06/query
- Week 4: Implemented CoT for complex symptoms (Strategy 2): 91% accuracy, 2.1s latency, $0.09/query
- Production (Week 5): Deployed with monitoring. After 30 days: 89% sustained accuracy (slight drift), 2.0s P95 latency, $0.08/query
The 18-point accuracy improvement from 73% to 91% required a modest cost increase ($0.04 → $0.09) but eliminated high-risk misdiagnoses that previously occurred 27% of the time.
Anti-Pattern Catalog: Common Failures and Fixes
Anti-Pattern 1: The Kitchen Sink Prompt
Bad: "You are an expert analyst with 20 years of experience in finance,
marketing, and technology. Analyze this data considering all possible
angles, industry trends, competitive dynamics, customer psychology,
macroeconomic factors, and emerging technologies. Be comprehensive,
accurate, creative, and practical. Provide actionable insights."Why it fails: Vague, conflicting directives confuse the model’s focus. “Be comprehensive” and “be practical” often conflict. Role-play bloat wastes tokens.
Fix (Strategy 1—structured architecture):
Good:
TASK: Identify top 3 revenue growth opportunities from Q4 sales data.
CONSTRAINTS:
- Focus on opportunities implementable within 90 days
- Minimum projected impact: $50K annual revenue
- Exclude solutions requiring new hires
OUTPUT FORMAT:
For each opportunity:
1. Description (2-3 sentences)
2. Revenue projection with assumptions
3. Implementation steps (bulleted list)Real consequence: The marketing agency reduced prompt processing cost by 47% by eliminating role-play preambles and vague instructions.
Anti-Pattern 2: Zero-Shot Overconfidence
Bad: "Classify this medical image as normal or abnormal."
(No examples, no criteria, no uncertainty handling)Why it fails: Medical diagnosis requires nuanced boundary recognition. Zero-shot prompts produce overconfident, wrong answers.
Fix (Strategy 4 – Few-Shot Learning):
Good:
Example 1: [Image A] - Normal: Clear margins, symmetrical structure, no lesions
Example 2: [Image B] - Abnormal: Irregular mass detected in upper right quadrant
Example 3: [Image C] - Uncertain: Subtle density variation, recommend specialist review
Your task: Classify [New Image]. If confidence <80%, output "Uncertain" and flag for human review.Real consequence: Radiology AI reduced the false positive rate from 31% to 9% by adding five examples and explicit uncertainty handling.
Anti-Pattern 3: Prompt Salad (Mixing Incompatible Strategies)
Bad: Combining zero-shot CoT + few-shot examples + RAG retrieval + JSON output requirements in single unstructured promptWhy it fails: Strategies interfere. CoT reasoning conflicts with rigid JSON formatting. Few-shot examples contradict the RAG context.
Fix (Strategy 7 – Prompt Chaining):
Good:
Chain Step 1 (RAG Retrieval): "Find top 5 relevant documents for query: [X]"
Chain Step 2 (CoT Analysis): "Given these documents, reason through implications step-by-step."
Chain Step 3 (Formatting): "Convert analysis to JSON schema: {finding: str, confidence: float, sources: list}"Real consequence: A financial services firm improved structured data extraction accuracy from 68% to 91% by separating retrieval, reasoning, and formatting into chain steps.
Anti-Pattern 4: Ignoring Cost-Performance Tradeoffs
Bad: Using GPT-4.5 Turbo ($10/1M tokens) for simple classification tasks achievable with Haiku ($0.25/1M tokens)Why it fails: Overpaying 40x for marginal accuracy gains destroys unit economics at scale.
Fix:
Good:
- Simple tasks (classification, extraction): Use Claude Haiku or GPT-4.5 Mini
- Moderate complexity (summarization, basic reasoning): Use Claude Sonnet 4.5 or GPT-4.5
- Complex reasoning (multi-step analysis, creative generation): Use Claude Opus 4.5 or GPT-4.5 Turbo
- Test-time compute tasks (mathematical proofs, code debugging): Use o3, DeepSeek R1Real consequence: E-commerce company reduced monthly AI costs from $47,000 to $12,000 by routing 78% of queries to cheaper models without accuracy loss.
Anti-Pattern 5: No Validation Pipeline
Bad: Deploy prompt to production based on 3 manual tests showing good resultsWhy it fails: Small sample size masks edge case failures. Production distribution differs from test cases.
Fix:
Good:
1. Create 100-500 example validation set covering edge cases
2. Automate evaluation (accuracy, latency, cost per query)
3. Test prompt variations A/B style
4. Monitor production metrics weekly (drift detection)
5. Rebuild validation set quarterly as use patterns evolveReal consequence: Customer support chatbot launched with 84% manual test accuracy. Production accuracy was measured after processing 1,000 queries, resulting in a score of 67%. Root cause: the test set missed 40% of real user question types. Proper validation prevented costly rollback.
Anti-Pattern 6: Overcomplicating Reasoning Model Prompts
Bad: Using few-shot examples + verbose CoT instructions with DeepSeek R1 or o3Why it fails: Reasoning models handle internal reasoning optimally with shorter prompts. External CoT instructions interfere with test-time compute.
Fix:
Good (for reasoning models):
"Task: Solve this calculus problem: [problem]
Expected output: Final answer with brief explanation."
(Model generates internal reasoning automatically during extended inference)Real consequence: The engineering team using DeepSeek R1 reduced prompt length by 73% (from 847 tokens to 227 tokens) and improved math problem accuracy from 81% to 89% by removing few-shot examples and CoT instructions.
What We Don’t Know: Current Gaps and Future Research
DeepSeek-R1 and OpenAI O3 introduced test-time compute, which lets models “think” before they answer. This feature is an example of reasoning model prompt optimization. Optimal prompting strategies for these systems remain under-researched as of January 2026. Early evidence suggests shorter, goal-focused prompts outperform verbose instructions, but comprehensive benchmarks haven’t been published. PromptHub’s preliminary analysis shows few-shot degraded R1 performance, but systematic testing across reasoning tasks is incomplete.
Long-context handling: Models now support 100K-1M+ token windows. How prompting strategies adapt beyond RAG in this massive context remains unclear. Is CoT beneficial or detrimental when dealing with 500K token inputs? Should structured outputs change for context-rich scenarios? Unknown.
Multimodal prompt composition: Best practices for combining text, images, and audio in single prompts lack empirical validation. Does order matter (text-first vs. image-first)? How much does textual description help or hinder visual understanding? Research gaps exist.
Prompt security and adversarial robustness: Prompt injection attacks evolved rapidly in 2025. Defensive prompting strategies exist but haven’t been systematically tested across attack vectors. Success rates of various defenses remain anecdotal rather than rigorously benchmarked.
Domain-specific transfer: How well do strategies tested in one domain (healthcare) transfer to others (legal, finance, creative)? Cross-domain validation studies are minimal. Most published results focus on single verticals.
Cost-quality tradeoffs at scale: As of January 2026, a comprehensive analysis comparing prompt complexity vs. inference cost across different model tiers (GPT-4.5 vs. Claude Sonnet 4.5 vs. Llama 4 vs. reasoning models) remains incomplete. Practitioners make decisions based on vendor benchmarks rather than independent validation.
Why these gaps matter: Teams deploying production systems lack evidence-based guidance for emerging capabilities. Conservative approaches (avoiding new model features) may sacrifice performance. Aggressive adoption risks costly failures. The field needs systematic benchmarking across providers, domains, and scale levels.
Forward-Looking: 2026-2027 Trajectory
Based on documented industry trends and vendor roadmaps (not speculation):
Prompt compression techniques: Microsoft Research’s January 2025 work on “prompt compression” demonstrated 40-60% token reduction while maintaining output quality. Commercial implementation is expected in Q2–Q3 of 2026. Impact: lower cost, faster inference for complex prompts.
Adaptive context selection: Dynamic retrieval systems that adjust context based on query complexity are entering the pilot phase. Instead of fixed top-k retrieval, systems vary between 3 and 15 passages depending on ambiguity detection. Early results show 12-18% accuracy gains over static retrieval.
Model-specific prompt libraries: Anthropic announced Claude-optimized prompt templates in December 2025. OpenAI, Google, and other vendors are developing similar resources. Expect standardized best-practice repositories by mid-2026, reducing trial-and-error experimentation time.
Regulatory impact: European AI Act provisions affecting prompt logging and auditability take effect in Q4 2026. Enterprise deployments will require prompt versioning, input/output logging, and bias auditing—shifting prompting from craft to governed process.
Observable signals to watch:
- Benchmark evolution: If GPQA Diamond scores continue climbing 20%+ annually, reasoning models will reduce the need for complex prompting
- Pricing changes: Token costs dropping to less than $0.50 per 1M tokens enable more verbose, fail-safe prompting
- Tool integration: Native code execution, web search, and database query tools in models reduce the need for manual chaining
- Specialization trend: Growth of domain-specific models (medical, legal, code) may favor simpler prompts over universal mega-prompts
These developments don’t eliminate prompt engineering—they shift it from a universal technique to contextual optimization.
Sources and Further Reading
Core research and benchmarks:
- Anthropic – Prompt Engineering Best Practices (November 2025) – Official Claude prompting guidelines, structured architecture patterns
- Medium—Prompt Engineering 2026 Series (January 2026) – Performance benchmarks: AIME math reasoning (+646%), GPQA science (+66%), SWE-Bench code (+305%)
- Medium – Understanding Reasoning Models: Test-Time Compute (January 2026)—DeepSeek R1 test-time compute analysis, prompting implications
- PromptHub – DeepSeek R1 Model Overview (January 2026) – Few-shot degradation in reasoning models, optimal prompting strategies
- Research and Markets—Prompt Engineering Market Report (2025)—Market size $1.13B (2025), middle estimate among research firms
- Fortune Business Insights – Prompt Engineering Market (2025) – Market size $505M (2025), conservative estimate
- Market Research Future – Prompt Engineering Market (2025) – Market size $2.8B (2025), optimistic estimate
- ZipRecruiter – Prompt Engineering Salary (January 2026) – Median $62,977/year, 25th percentile $47K, 75th percentile $72K
- Coursera – Prompt Engineering Salary Guide (December 2025) – Specialized roles median $126K total comp in tech hubs
- Salesforce Ben—Prompt Engineering Jobs Analysis (2025)—LinkedIn job decline, McKinsey survey (7% hiring rate), role absorption
- Google Brain—Chain-of-Thought Prompting Paper (2022)—Original CoT research, foundation for reasoning strategies
- IBM – Chain of Thoughts Analysis (November 2025) – Updated CoT performance analysis, multi-step problem-solving gains
- AWS – What is RAG? (2025) – Technical overview of Retrieval-Augmented Generation architecture
- AIMultiple – RAG Research Study (2026) – Llama 4 Scout benchmark: RAG 87% vs. Long context 74%, embedding model comparison
- TuringPost – 12 RAG Types Analysis (2025) – HiFi-RAG, Bidirectional RAG, GraphRAG variants, and use cases
- Palantir – AIP Prompt Engineering Best Practices (2025) – Few-shot optimization, example count testing
- DigitalOcean – Prompt Engineering Best Practices (2025) – DSPy framework, auto-optimization benchmarks, prompt chaining
- Lakera – Prompt Engineering Guide (2025) – Production legal tech case studies, security considerations
- PromptBuilder – Claude Best Practices 2026 (December 2025) – Contract-style prompts, 4-block user prompts
- Refonte Learning—Prompt Engineering Trends 2026 (2025)—Multimodal prompting, market evolution analysis
- Dextra Labs – Enterprise Prompt Engineering Use Cases (2025) – Enterprise AI adoption 15% → 52% (2023-2025), regulatory impact
- Codecademy – Chain-of-Thought Prompting Guide (2025)—CoT accuracy benchmarks, implementation examples
- Analytics Vidhya—RAG Projects Guide (January 2026)—RAG failure modes, adaptive context selection
- Learn Prompting—CoT Documentation (2025)—Parameter scaling requirements (<100B limitation)
- News.AakashG – Prompt Engineering Deep Dive (2025) – Bolt CEO case study (34% accuracy improvement), meta-prompting techniques
- Prompting Guide – Introduction and Tips (2025) – Microsoft prompt compression research (40-60% token reduction)
- OpenAI – Structured Outputs Documentation (2025) – Native JSON schema enforcement, API implementation
- Agenta—Guide to Structured Outputs with LLMs (2025)—Outlines, Instructor, Guidance library comparisons
- MPGOne – JSON Prompt Guide (2026) – Enterprise adoption statistics (70%), error reduction benchmarks
Industry documentation:
- Anthropic Claude Documentation – Official API docs, model capabilities, pricing
- OpenAI Platform Documentation – GPT-4.5 series specs, API reference
- Google AI Studio—Gemini Documentation—Gemini Pro Vision capabilities, multimodal prompting


